School of Software Technology, Zhejiang University, China

I obtained my PhD in 2025 from the School of Computer Science and Technology at Zhejiang University, under the supervision of Professor Shuiguang Deng. During Sep. 2024 - Mar. 2025, I was a Visiting PhD Student at the School of Computing, National University of Singapore, with the supervision from Prof. Bingsheng He. During Jun. 2023 - Aug. 2025, I worked as a research intern at Tongyi Lab, Alibaba Group.
My research interests include 1) data provision for and with LLMs, 2) federated learning and federated fine-tuning of LLMs, and 3) LLM-based multi-agent systems. So far, I have published more than 10 CCF-A ranked papers in IEEE TPAMI, IEEE TMC, IEEE TSC, ICML, KDD, WWW, AAAI, ACL, ICDE, etc.
For students who are interested in joining our research group, please feel free to contact me at zhenqin@zju.edu.cn.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Zhejiang UniversityCollege of Computer Science and Technology
Zhejiang UniversityCollege of Computer Science and Technology
Ph.D. StudentSep. 2021 - Mar. 2025 -
 Shanghai UniversityM.S. in Computer ScienceSep. 2018 - Jul. 2021
Shanghai UniversityM.S. in Computer ScienceSep. 2018 - Jul. 2021 -
Shanghai UniversityB.S. in Computer ScienceSep. 2014 - Jul. 2018
Honors & Awards
-
Excellent Graduate of Zhejiang Province2025
-
National Scholarship for Doctoral Students (in Zhejiang University)2024
-
The Best Research Award in Data Science of Zhejiang University2024
-
Excellent Graduate of Shanghai2021
-
National Scholarship for Master's Students (in Shanghai University)2020
-
National Scholarship for Master's Students (in Shanghai University)2019
News
Selected Publications (view all )
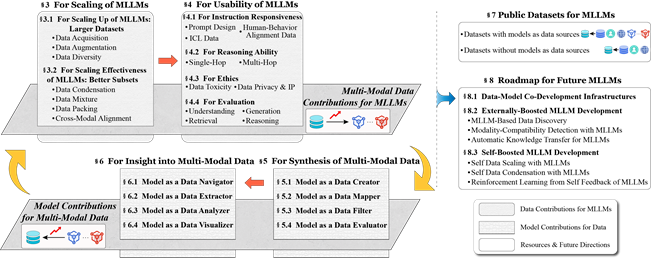
The Synergy Between Data and Multi-Modal Large Language Models: A Survey From Co-Development Perspective
Zhen Qin†, Daoyuan Chen†, Wenhao Zhang, Liuyi Yao, Yilun Huang, Bolin Ding, Yaliang Li*, Shuiguang Deng* († equal contribution, * corresponding author)
IEEE Transactions on Pattern Analysis and Machine Intelligence 2025
Recent years have witnessed the rapid development of large language models (LLMs). Mmodal LLMs (MLLMs) extend modality from text to various domains, attracting widespread attention due to their diverse application scenarios. As LLMs and MLLMs rely on vast amounts of model parameters and data to achieve emergent capabilities, the importance of data is gaining increasing recognition. Reviewing recent data-driven works for MLLMs, we find that the development of models and data is not two separate paths but rather interconnected. Vaster and higher-quality data improve MLLM performance, while MLLMs, in turn, facilitate the development of data. The co-development of modal data and MLLMs requires a clear view of 1) at which development stages of MLLMs specific data-centric approaches can be employed to enhance certain MLLM capabilities, and 2) how MLLMs, using these capabilities, can contribute to mmodal data in specific roles. To promote data-model co-development for MLLM communities, we systematically review existing works on MLLMs from the data-model co-development perspective.
The Synergy Between Data and Multi-Modal Large Language Models: A Survey From Co-Development Perspective
Zhen Qin†, Daoyuan Chen†, Wenhao Zhang, Liuyi Yao, Yilun Huang, Bolin Ding, Yaliang Li*, Shuiguang Deng* († equal contribution, * corresponding author)
IEEE Transactions on Pattern Analysis and Machine Intelligence 2025
Recent years have witnessed the rapid development of large language models (LLMs). Mmodal LLMs (MLLMs) extend modality from text to various domains, attracting widespread attention due to their diverse application scenarios. As LLMs and MLLMs rely on vast amounts of model parameters and data to achieve emergent capabilities, the importance of data is gaining increasing recognition. Reviewing recent data-driven works for MLLMs, we find that the development of models and data is not two separate paths but rather interconnected. Vaster and higher-quality data improve MLLM performance, while MLLMs, in turn, facilitate the development of data. The co-development of modal data and MLLMs requires a clear view of 1) at which development stages of MLLMs specific data-centric approaches can be employed to enhance certain MLLM capabilities, and 2) how MLLMs, using these capabilities, can contribute to mmodal data in specific roles. To promote data-model co-development for MLLM communities, we systematically review existing works on MLLMs from the data-model co-development perspective.

Federated Data-Efficient Instruction Tuning for Large Language Models
Zhen Qin, Zhaomin Wu*, Bingsheng He, Shuiguang Deng (* corresponding author)
Annual Meeting of the Association for Computational Linguistics (ACL) 2025
Instruction tuning helps improve pretrained large language models (LLMs) in terms of the responsiveness to human instructions, which is benefited from diversified instruction data. Federated learning extends the sources of instruction data by exploiting the diversified client-side data, making it increasingly popular for tuning LLMs. Existing approaches of federated LLM tuning typically traverse all local data during local training, bringing excessive computation overhead and posing a risk of overfitting local data. Thus, a federated data-efficient instruction tuning approach, which consumes relatively little data from the entire dataset, is needed. In response, this work introduces an approach of federated data-efficient instruction tuning for LLMs, FedHDS, which utilizes a representative subset of edge-side data, coreset, to tune the LLM. It reduces the redundancy of data samples at both intra-client and inter-client levels through a hierarchical data selection framework performed by jointly selecting a small number of representative data samples for local training without sharing the raw data. Extensive experiments conducted across six scenarios with various LLMs, datasets and data partitions demonstrate that FedHDS significantly reduces the amount of data required for fine-tuning while improving the responsiveness of the instruction-tuned LLMs to unseen tasks.
Federated Data-Efficient Instruction Tuning for Large Language Models
Zhen Qin, Zhaomin Wu*, Bingsheng He, Shuiguang Deng (* corresponding author)
Annual Meeting of the Association for Computational Linguistics (ACL) 2025
Instruction tuning helps improve pretrained large language models (LLMs) in terms of the responsiveness to human instructions, which is benefited from diversified instruction data. Federated learning extends the sources of instruction data by exploiting the diversified client-side data, making it increasingly popular for tuning LLMs. Existing approaches of federated LLM tuning typically traverse all local data during local training, bringing excessive computation overhead and posing a risk of overfitting local data. Thus, a federated data-efficient instruction tuning approach, which consumes relatively little data from the entire dataset, is needed. In response, this work introduces an approach of federated data-efficient instruction tuning for LLMs, FedHDS, which utilizes a representative subset of edge-side data, coreset, to tune the LLM. It reduces the redundancy of data samples at both intra-client and inter-client levels through a hierarchical data selection framework performed by jointly selecting a small number of representative data samples for local training without sharing the raw data. Extensive experiments conducted across six scenarios with various LLMs, datasets and data partitions demonstrate that FedHDS significantly reduces the amount of data required for fine-tuning while improving the responsiveness of the instruction-tuned LLMs to unseen tasks.

Federated Full-Parameter Tuning of Billion-Sized Language Models with Communication Cost under 18 Kilobytes
Zhen Qin, Daoyuan Chen, Bingchen Qian, Bolin Ding, Yaliang Li*, Shuiguang Deng* (* corresponding author)
International Conference on Machine Learning (ICML) 2024
Pre-trained large language models (LLMs) require fine-tuning to improve their responsiveness to natural language instructions. Federated learning (FL) offers a way to perform fine-tuning using the abundant data on end devices without compromising data privacy. Most existing federated fine-tuning methods for LLMs rely on parameter-efficient fine-tuning techniques, which may not reach the performance heights possible with full-parameter tuning. However, the communication overhead associated with full-parameter tuning is prohibitively high for both servers and clients. This work introduces FedKSeed, a novel approach that employs zeroth-order optimization (ZOO) with a set of random seeds. It enables federated full-parameter tuning of billion-sized LLMs directly on devices. Our method significantly reduces transmission requirements between the server and clients to just a few scalar gradients and random seeds, amounting to only a few thousand bytes. Building on this, we develop a strategy to assess the significance of ZOO perturbations for FL, allowing for probability-differentiated seed sampling. This prioritizes perturbations that have a greater impact on model accuracy. Experiments across six scenarios with different LLMs, datasets and data partitions demonstrate that our approach outperforms existing federated LLM fine-tuning methods in terms of both communication efficiency and new task generalization.
Federated Full-Parameter Tuning of Billion-Sized Language Models with Communication Cost under 18 Kilobytes
Zhen Qin, Daoyuan Chen, Bingchen Qian, Bolin Ding, Yaliang Li*, Shuiguang Deng* (* corresponding author)
International Conference on Machine Learning (ICML) 2024
Pre-trained large language models (LLMs) require fine-tuning to improve their responsiveness to natural language instructions. Federated learning (FL) offers a way to perform fine-tuning using the abundant data on end devices without compromising data privacy. Most existing federated fine-tuning methods for LLMs rely on parameter-efficient fine-tuning techniques, which may not reach the performance heights possible with full-parameter tuning. However, the communication overhead associated with full-parameter tuning is prohibitively high for both servers and clients. This work introduces FedKSeed, a novel approach that employs zeroth-order optimization (ZOO) with a set of random seeds. It enables federated full-parameter tuning of billion-sized LLMs directly on devices. Our method significantly reduces transmission requirements between the server and clients to just a few scalar gradients and random seeds, amounting to only a few thousand bytes. Building on this, we develop a strategy to assess the significance of ZOO perturbations for FL, allowing for probability-differentiated seed sampling. This prioritizes perturbations that have a greater impact on model accuracy. Experiments across six scenarios with different LLMs, datasets and data partitions demonstrate that our approach outperforms existing federated LLM fine-tuning methods in terms of both communication efficiency and new task generalization.