2026
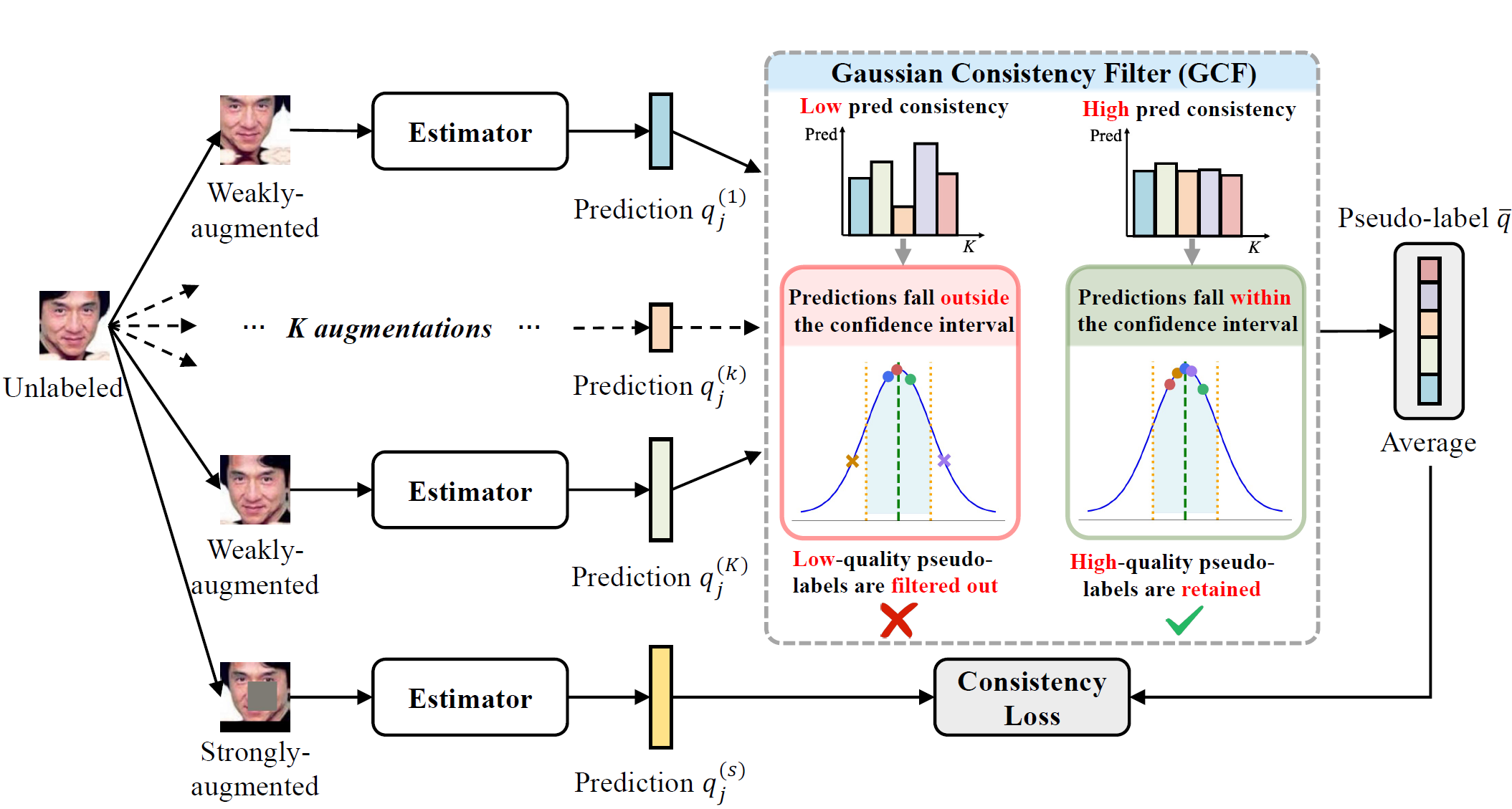
GaussianMatch: Semi-Supervised Regression with Pseudo-Label Filtering via Multi-View Gaussian Consistency
Yin Wang, Hao Lu, Zixuan Wang, Zhen Qin*, Li Kuang, Mengchu Zhou, Shuiguang Deng* (* corresponding author)
IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR) 2026
Semi-Supervised Regression (SSR) is essential in domains like sentiment analysis, healthcare, etc., where labeled data is limited but unlabeled data is plentiful. Despite its practical importance, SSR remains underexplored due to the lack of effective pseudo-labeling strategies for continuous outputs. Unlike classification, regression lacks inherent confidence measures, making it harder to filter and trust pseudo-labels. This limitation permits low-quality pseudo-labels to propagate during training without proper validation, significantly amplifying prediction errors in semi-supervised regression frameworks. In this work, we propose GaussianMatch, a novel SSR framework enabling high-quality pseudo-label filtering, which selects reliable pseudo-labels through multi-view prediction consistency under feature-space smoothness assumptions. Our framework introduces two key innovations: 1) Gaussian Consistency Filter (GCF) that quantifies prediction consistency across weakly augmented views through Gaussian similarity scoring, retaining pseudo-labels only when all predictions fall within a confidence interval; 2) Adaptive Gaussian Standard Deviation Smoothing (AGDS) that enhances GCF's robustness through a Bayesian-regularized curriculum that phases confidence intervals from warm-up conservative bounds to progressively tightened thresholds. The use of AGDS ensures stable and reliable pseudo-label filtering throughout training. Extensive experiments demonstrate that GaussianMatch performs strongly across varying data conditions, showing notable robustness under extreme label scarcity. For instance, it outperforms the state of the art on UTKFace with only 30 labels, reducing error by 15.36% and improving the Coefficient of Determination by 50.21%.
GaussianMatch: Semi-Supervised Regression with Pseudo-Label Filtering via Multi-View Gaussian Consistency
Yin Wang, Hao Lu, Zixuan Wang, Zhen Qin*, Li Kuang, Mengchu Zhou, Shuiguang Deng* (* corresponding author)
IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR) 2026
Semi-Supervised Regression (SSR) is essential in domains like sentiment analysis, healthcare, etc., where labeled data is limited but unlabeled data is plentiful. Despite its practical importance, SSR remains underexplored due to the lack of effective pseudo-labeling strategies for continuous outputs. Unlike classification, regression lacks inherent confidence measures, making it harder to filter and trust pseudo-labels. This limitation permits low-quality pseudo-labels to propagate during training without proper validation, significantly amplifying prediction errors in semi-supervised regression frameworks. In this work, we propose GaussianMatch, a novel SSR framework enabling high-quality pseudo-label filtering, which selects reliable pseudo-labels through multi-view prediction consistency under feature-space smoothness assumptions. Our framework introduces two key innovations: 1) Gaussian Consistency Filter (GCF) that quantifies prediction consistency across weakly augmented views through Gaussian similarity scoring, retaining pseudo-labels only when all predictions fall within a confidence interval; 2) Adaptive Gaussian Standard Deviation Smoothing (AGDS) that enhances GCF's robustness through a Bayesian-regularized curriculum that phases confidence intervals from warm-up conservative bounds to progressively tightened thresholds. The use of AGDS ensures stable and reliable pseudo-label filtering throughout training. Extensive experiments demonstrate that GaussianMatch performs strongly across varying data conditions, showing notable robustness under extreme label scarcity. For instance, it outperforms the state of the art on UTKFace with only 30 labels, reducing error by 15.36% and improving the Coefficient of Determination by 50.21%.

Personalized Federated Fine-Tuning for LLMs via Data-Driven Heterogeneous Model Architectures
Yicheng Zhang, Zhen Qin*, Zhaomin Wu, Jian Hou, Shuiguang Deng* (* corresponding author)
The Web Conference (WWW) 2026
Large language models (LLMs) are increasingly powering web-based applications, whose effectiveness relies on fine-tuning with large-scale instruction data. However, such data often contains valuable or sensitive information that limits its public sharing among business organizations. Federated learning (FL) enables collaborative fine-tuning of LLMs without accessing raw data. Existing approaches to federated LLM fine-tuning usually adopt a uniform model architecture, making it challenging to fit highly heterogeneous client-side data in varying domains and tasks, e.g., hospitals and financial institutions conducting federated fine-tuning may require different LLM architectures due to the distinct nature of their domains and tasks. To address this, we propose FedAMoLE, a lightweight personalized FL framework that enables data-driven heterogeneous model architectures. It features a heterogeneous mixture of low-rank adaptation (LoRA) experts module to aggregate architecturally heterogeneous models and a reverse selection-based expert assignment strategy to tailor model architectures for each client based on data distributions. Experiments across seven scenarios demonstrate that FedAMoLE improves client-side performance by an average of 5.97% over existing approaches while maintaining practical memory, communication, and computation overhead.
Personalized Federated Fine-Tuning for LLMs via Data-Driven Heterogeneous Model Architectures
Yicheng Zhang, Zhen Qin*, Zhaomin Wu, Jian Hou, Shuiguang Deng* (* corresponding author)
The Web Conference (WWW) 2026
Large language models (LLMs) are increasingly powering web-based applications, whose effectiveness relies on fine-tuning with large-scale instruction data. However, such data often contains valuable or sensitive information that limits its public sharing among business organizations. Federated learning (FL) enables collaborative fine-tuning of LLMs without accessing raw data. Existing approaches to federated LLM fine-tuning usually adopt a uniform model architecture, making it challenging to fit highly heterogeneous client-side data in varying domains and tasks, e.g., hospitals and financial institutions conducting federated fine-tuning may require different LLM architectures due to the distinct nature of their domains and tasks. To address this, we propose FedAMoLE, a lightweight personalized FL framework that enables data-driven heterogeneous model architectures. It features a heterogeneous mixture of low-rank adaptation (LoRA) experts module to aggregate architecturally heterogeneous models and a reverse selection-based expert assignment strategy to tailor model architectures for each client based on data distributions. Experiments across seven scenarios demonstrate that FedAMoLE improves client-side performance by an average of 5.97% over existing approaches while maintaining practical memory, communication, and computation overhead.
2025
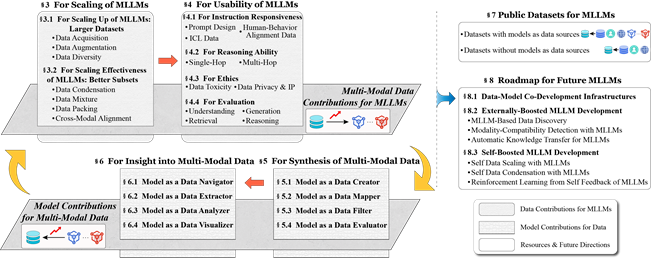
The Synergy Between Data and Multi-Modal Large Language Models: A Survey From Co-Development Perspective
Zhen Qin†, Daoyuan Chen†, Wenhao Zhang, Liuyi Yao, Yilun Huang, Bolin Ding, Yaliang Li*, Shuiguang Deng* († equal contribution, * corresponding author)
IEEE Transactions on Pattern Analysis and Machine Intelligence 2025
Recent years have witnessed the rapid development of large language models (LLMs). Mmodal LLMs (MLLMs) extend modality from text to various domains, attracting widespread attention due to their diverse application scenarios. As LLMs and MLLMs rely on vast amounts of model parameters and data to achieve emergent capabilities, the importance of data is gaining increasing recognition. Reviewing recent data-driven works for MLLMs, we find that the development of models and data is not two separate paths but rather interconnected. Vaster and higher-quality data improve MLLM performance, while MLLMs, in turn, facilitate the development of data. The co-development of modal data and MLLMs requires a clear view of 1) at which development stages of MLLMs specific data-centric approaches can be employed to enhance certain MLLM capabilities, and 2) how MLLMs, using these capabilities, can contribute to mmodal data in specific roles. To promote data-model co-development for MLLM communities, we systematically review existing works on MLLMs from the data-model co-development perspective.
The Synergy Between Data and Multi-Modal Large Language Models: A Survey From Co-Development Perspective
Zhen Qin†, Daoyuan Chen†, Wenhao Zhang, Liuyi Yao, Yilun Huang, Bolin Ding, Yaliang Li*, Shuiguang Deng* († equal contribution, * corresponding author)
IEEE Transactions on Pattern Analysis and Machine Intelligence 2025
Recent years have witnessed the rapid development of large language models (LLMs). Mmodal LLMs (MLLMs) extend modality from text to various domains, attracting widespread attention due to their diverse application scenarios. As LLMs and MLLMs rely on vast amounts of model parameters and data to achieve emergent capabilities, the importance of data is gaining increasing recognition. Reviewing recent data-driven works for MLLMs, we find that the development of models and data is not two separate paths but rather interconnected. Vaster and higher-quality data improve MLLM performance, while MLLMs, in turn, facilitate the development of data. The co-development of modal data and MLLMs requires a clear view of 1) at which development stages of MLLMs specific data-centric approaches can be employed to enhance certain MLLM capabilities, and 2) how MLLMs, using these capabilities, can contribute to mmodal data in specific roles. To promote data-model co-development for MLLM communities, we systematically review existing works on MLLMs from the data-model co-development perspective.

SeMi: When Imbalanced Semi-Supervised Learning Meets Mining Hard Examples
Yin Wang, Zixuan Wang, Hao Lu, Zhen Qin*, Hailiang Zhao, Guanjie Cheng, Ge Su, Li Kuang, Mengchu Zhou, Shuiguang Deng* (* corresponding author)
ACM International Conference on Multimedia (ACM MM) 2025
Semi-Supervised Learning (SSL) can leverage abundant unlabeled data to boost model performance. However, the class-imbalanced data distribution in real-world scenarios poses great challenges to SSL, resulting in performance degradation. Existing class-imbalanced semi-supervised learning (CISSL) methods mainly focus on rebalancing datasets but ignore the potential of using hard examples to enhance performance, making it difficult to fully harness the power of unlabeled data even with sophisticated algorithms. To address this issue, we propose a method that enhances the performance of Imbalanced Semi-Supervised Learning by Mining Hard Examples (SeMi). This method distinguishes the entropy differences among logits of hard and easy examples, thereby identifying hard examples and increasing the utility of unlabeled data, better addressing the imbalance problem in CISSL. In addition, we maintain a class-balanced memory bank with confidence decay for storing high-confidence embeddings to enhance the pseudo-labels' reliability. Although our method is simple, it is effective and seamlessly integrates with existing approaches. We perform comprehensive experiments on standard CISSL benchmarks and experimentally demonstrate that our proposed SeMi outperforms existing state-of-the-art methods on multiple benchmarks, especially in reversed scenarios, where our best result shows approximately a 54.8\% improvement over the baseline methods.
SeMi: When Imbalanced Semi-Supervised Learning Meets Mining Hard Examples
Yin Wang, Zixuan Wang, Hao Lu, Zhen Qin*, Hailiang Zhao, Guanjie Cheng, Ge Su, Li Kuang, Mengchu Zhou, Shuiguang Deng* (* corresponding author)
ACM International Conference on Multimedia (ACM MM) 2025
Semi-Supervised Learning (SSL) can leverage abundant unlabeled data to boost model performance. However, the class-imbalanced data distribution in real-world scenarios poses great challenges to SSL, resulting in performance degradation. Existing class-imbalanced semi-supervised learning (CISSL) methods mainly focus on rebalancing datasets but ignore the potential of using hard examples to enhance performance, making it difficult to fully harness the power of unlabeled data even with sophisticated algorithms. To address this issue, we propose a method that enhances the performance of Imbalanced Semi-Supervised Learning by Mining Hard Examples (SeMi). This method distinguishes the entropy differences among logits of hard and easy examples, thereby identifying hard examples and increasing the utility of unlabeled data, better addressing the imbalance problem in CISSL. In addition, we maintain a class-balanced memory bank with confidence decay for storing high-confidence embeddings to enhance the pseudo-labels' reliability. Although our method is simple, it is effective and seamlessly integrates with existing approaches. We perform comprehensive experiments on standard CISSL benchmarks and experimentally demonstrate that our proposed SeMi outperforms existing state-of-the-art methods on multiple benchmarks, especially in reversed scenarios, where our best result shows approximately a 54.8\% improvement over the baseline methods.

Federated Data-Efficient Instruction Tuning for Large Language Models
Zhen Qin, Zhaomin Wu*, Bingsheng He, Shuiguang Deng (* corresponding author)
Annual Meeting of the Association for Computational Linguistics (ACL) 2025
Instruction tuning helps improve pretrained large language models (LLMs) in terms of the responsiveness to human instructions, which is benefited from diversified instruction data. Federated learning extends the sources of instruction data by exploiting the diversified client-side data, making it increasingly popular for tuning LLMs. Existing approaches of federated LLM tuning typically traverse all local data during local training, bringing excessive computation overhead and posing a risk of overfitting local data. Thus, a federated data-efficient instruction tuning approach, which consumes relatively little data from the entire dataset, is needed. In response, this work introduces an approach of federated data-efficient instruction tuning for LLMs, FedHDS, which utilizes a representative subset of edge-side data, coreset, to tune the LLM. It reduces the redundancy of data samples at both intra-client and inter-client levels through a hierarchical data selection framework performed by jointly selecting a small number of representative data samples for local training without sharing the raw data. Extensive experiments conducted across six scenarios with various LLMs, datasets and data partitions demonstrate that FedHDS significantly reduces the amount of data required for fine-tuning while improving the responsiveness of the instruction-tuned LLMs to unseen tasks.
Federated Data-Efficient Instruction Tuning for Large Language Models
Zhen Qin, Zhaomin Wu*, Bingsheng He, Shuiguang Deng (* corresponding author)
Annual Meeting of the Association for Computational Linguistics (ACL) 2025
Instruction tuning helps improve pretrained large language models (LLMs) in terms of the responsiveness to human instructions, which is benefited from diversified instruction data. Federated learning extends the sources of instruction data by exploiting the diversified client-side data, making it increasingly popular for tuning LLMs. Existing approaches of federated LLM tuning typically traverse all local data during local training, bringing excessive computation overhead and posing a risk of overfitting local data. Thus, a federated data-efficient instruction tuning approach, which consumes relatively little data from the entire dataset, is needed. In response, this work introduces an approach of federated data-efficient instruction tuning for LLMs, FedHDS, which utilizes a representative subset of edge-side data, coreset, to tune the LLM. It reduces the redundancy of data samples at both intra-client and inter-client levels through a hierarchical data selection framework performed by jointly selecting a small number of representative data samples for local training without sharing the raw data. Extensive experiments conducted across six scenarios with various LLMs, datasets and data partitions demonstrate that FedHDS significantly reduces the amount of data required for fine-tuning while improving the responsiveness of the instruction-tuned LLMs to unseen tasks.

ExploraCoder: Advancing Code Generation for Multiple Unseen APIs via Planning and Chained Exploration
Yunkun Wang, Yue Zhang, Zhen Qin, Chen Zhi*, Binhua Li, Fei Huang, Yongbin Li*, Shuiguang Deng* (* corresponding author)
Annual Meeting of the Association for Computational Linguistics (ACL) 2025
Large language models face intrinsic limitations in coding with APIs that are unseen in their training corpora. As libraries continuously evolve, it becomes impractical to exhaustively retrain LLMs with new API knowledge. This limitation hampers LLMs from solving programming problems which require newly introduced or privately maintained libraries. Inspired by exploratory programming paradigm in human behavior, we propose ExploraCoder, a training-free framework that empowers LLMs to invoke multiple unseen APIs in code solution by (1) planning a complex problem into several API invocation subtasks, and (2) experimenting with correct API usage at intermediate steps through a novel chain-of-API-exploration. We conduct evaluation on program synthesizing tasks involving complex API interactions. Experimental results demonstrate that ExploraCoder significantly improves performance for models lacking prior API knowledge, achieving absolute increases of up to 11.99% over retrieval-based approaches and 17.28% over pretraining-based methods in pass@10.
ExploraCoder: Advancing Code Generation for Multiple Unseen APIs via Planning and Chained Exploration
Yunkun Wang, Yue Zhang, Zhen Qin, Chen Zhi*, Binhua Li, Fei Huang, Yongbin Li*, Shuiguang Deng* (* corresponding author)
Annual Meeting of the Association for Computational Linguistics (ACL) 2025
Large language models face intrinsic limitations in coding with APIs that are unseen in their training corpora. As libraries continuously evolve, it becomes impractical to exhaustively retrain LLMs with new API knowledge. This limitation hampers LLMs from solving programming problems which require newly introduced or privately maintained libraries. Inspired by exploratory programming paradigm in human behavior, we propose ExploraCoder, a training-free framework that empowers LLMs to invoke multiple unseen APIs in code solution by (1) planning a complex problem into several API invocation subtasks, and (2) experimenting with correct API usage at intermediate steps through a novel chain-of-API-exploration. We conduct evaluation on program synthesizing tasks involving complex API interactions. Experimental results demonstrate that ExploraCoder significantly improves performance for models lacking prior API knowledge, achieving absolute increases of up to 11.99% over retrieval-based approaches and 17.28% over pretraining-based methods in pass@10.
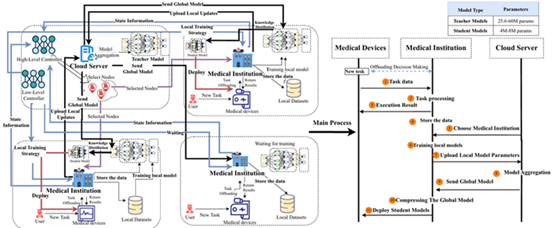
Federated Knowledge Distillation using Hierarchical Reinforcement Learning in Resource-Constrained IoT Edge-Cloud Computing Environments
Yishan Chen, Zhiqiang Wang, Huashuai Cai, Zhen Qin, Shuiguang Deng
IEEE Transactions on Mobile Computing (TMC) 2025
With the development of Federated Learning (FL) in IoT Edge-Cloud Computing environments, mobile terminals are able to cooperate without the leakage on raw data. However, factors including the terminals' high mobility and the network fluctuations make the cooperator selection during FL training extremely complex. Under the distributed cooperation, traditional FL strategies show certain limitations and cannot always select the available nodes when training, leading to the difficulties in energy and latency optimization. In this paper, we propose a Hierarchical Reinforcement Learning (HRL)-based federated knowledge distillation (HRL-FedKD) framework in which both high-level and low-level controllers utilize the Double Deep Q-Network (DDQN) algorithm. The high-level controller selects the nodes participating in FL training, while the low-level controller determines the number of local training epochs for each node. After training, the global model will be compressed into a lightweight model by knowledge distillation (KD) in deployment while preserving the personalization of local models. The experiments were conducted using Chest X-Ray and Brain Tumor MRI datasets to validate the proposed FL strategy. The results demonstrate that the HRL-FedKD framework can effectively optimize latency and energy consumption in complex state spaces.
Federated Knowledge Distillation using Hierarchical Reinforcement Learning in Resource-Constrained IoT Edge-Cloud Computing Environments
Yishan Chen, Zhiqiang Wang, Huashuai Cai, Zhen Qin, Shuiguang Deng
IEEE Transactions on Mobile Computing (TMC) 2025
With the development of Federated Learning (FL) in IoT Edge-Cloud Computing environments, mobile terminals are able to cooperate without the leakage on raw data. However, factors including the terminals' high mobility and the network fluctuations make the cooperator selection during FL training extremely complex. Under the distributed cooperation, traditional FL strategies show certain limitations and cannot always select the available nodes when training, leading to the difficulties in energy and latency optimization. In this paper, we propose a Hierarchical Reinforcement Learning (HRL)-based federated knowledge distillation (HRL-FedKD) framework in which both high-level and low-level controllers utilize the Double Deep Q-Network (DDQN) algorithm. The high-level controller selects the nodes participating in FL training, while the low-level controller determines the number of local training epochs for each node. After training, the global model will be compressed into a lightweight model by knowledge distillation (KD) in deployment while preserving the personalization of local models. The experiments were conducted using Chest X-Ray and Brain Tumor MRI datasets to validate the proposed FL strategy. The results demonstrate that the HRL-FedKD framework can effectively optimize latency and energy consumption in complex state spaces.

Vertical Federated Learning in Practice: The Good, the Bad, and the Ugly
Zhaomin Wu, Zhen Qin, Junyi Hou, Haodong Zhao, Qinbin Li, Bingsheng He, Lixin Fan
arXiv:2502.08160 2025
Vertical Federated Learning (VFL) is a privacy-preserving collaborative learning paradigm that enables multiple parties with distinct feature sets to jointly train machine learning models without sharing their raw data. Despite its potential to facilitate cross-organizational collaborations, the deployment of VFL systems in real-world applications remains limited. To investigate the gap between existing VFL research and practical deployment, this survey analyzes the real-world data distributions in potential VFL applications and identifies four key findings that highlight this gap. We propose a novel data-oriented taxonomy of VFL algorithms based on real VFL data distributions. Our comprehensive review of existing VFL algorithms reveals that some common practical VFL scenarios have few or no viable solutions. Based on these observations, we outline key research directions aimed at bridging the gap between current VFL research and real-world applications.
Vertical Federated Learning in Practice: The Good, the Bad, and the Ugly
Zhaomin Wu, Zhen Qin, Junyi Hou, Haodong Zhao, Qinbin Li, Bingsheng He, Lixin Fan
arXiv:2502.08160 2025
Vertical Federated Learning (VFL) is a privacy-preserving collaborative learning paradigm that enables multiple parties with distinct feature sets to jointly train machine learning models without sharing their raw data. Despite its potential to facilitate cross-organizational collaborations, the deployment of VFL systems in real-world applications remains limited. To investigate the gap between existing VFL research and practical deployment, this survey analyzes the real-world data distributions in potential VFL applications and identifies four key findings that highlight this gap. We propose a novel data-oriented taxonomy of VFL algorithms based on real VFL data distributions. Our comprehensive review of existing VFL algorithms reveals that some common practical VFL scenarios have few or no viable solutions. Based on these observations, we outline key research directions aimed at bridging the gap between current VFL research and real-world applications.
2024

Federated Full-Parameter Tuning of Billion-Sized Language Models with Communication Cost under 18 Kilobytes
Zhen Qin, Daoyuan Chen, Bingchen Qian, Bolin Ding, Yaliang Li*, Shuiguang Deng* (* corresponding author)
International Conference on Machine Learning (ICML) 2024
Pre-trained large language models (LLMs) require fine-tuning to improve their responsiveness to natural language instructions. Federated learning (FL) offers a way to perform fine-tuning using the abundant data on end devices without compromising data privacy. Most existing federated fine-tuning methods for LLMs rely on parameter-efficient fine-tuning techniques, which may not reach the performance heights possible with full-parameter tuning. However, the communication overhead associated with full-parameter tuning is prohibitively high for both servers and clients. This work introduces FedKSeed, a novel approach that employs zeroth-order optimization (ZOO) with a set of random seeds. It enables federated full-parameter tuning of billion-sized LLMs directly on devices. Our method significantly reduces transmission requirements between the server and clients to just a few scalar gradients and random seeds, amounting to only a few thousand bytes. Building on this, we develop a strategy to assess the significance of ZOO perturbations for FL, allowing for probability-differentiated seed sampling. This prioritizes perturbations that have a greater impact on model accuracy. Experiments across six scenarios with different LLMs, datasets and data partitions demonstrate that our approach outperforms existing federated LLM fine-tuning methods in terms of both communication efficiency and new task generalization.
Federated Full-Parameter Tuning of Billion-Sized Language Models with Communication Cost under 18 Kilobytes
Zhen Qin, Daoyuan Chen, Bingchen Qian, Bolin Ding, Yaliang Li*, Shuiguang Deng* (* corresponding author)
International Conference on Machine Learning (ICML) 2024
Pre-trained large language models (LLMs) require fine-tuning to improve their responsiveness to natural language instructions. Federated learning (FL) offers a way to perform fine-tuning using the abundant data on end devices without compromising data privacy. Most existing federated fine-tuning methods for LLMs rely on parameter-efficient fine-tuning techniques, which may not reach the performance heights possible with full-parameter tuning. However, the communication overhead associated with full-parameter tuning is prohibitively high for both servers and clients. This work introduces FedKSeed, a novel approach that employs zeroth-order optimization (ZOO) with a set of random seeds. It enables federated full-parameter tuning of billion-sized LLMs directly on devices. Our method significantly reduces transmission requirements between the server and clients to just a few scalar gradients and random seeds, amounting to only a few thousand bytes. Building on this, we develop a strategy to assess the significance of ZOO perturbations for FL, allowing for probability-differentiated seed sampling. This prioritizes perturbations that have a greater impact on model accuracy. Experiments across six scenarios with different LLMs, datasets and data partitions demonstrate that our approach outperforms existing federated LLM fine-tuning methods in terms of both communication efficiency and new task generalization.
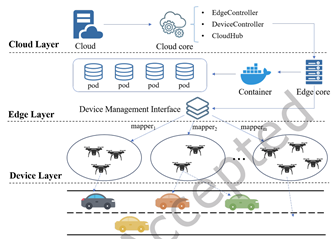
Adaptive Scheduling of High-Availability Drone Swarms for Congestion Alleviation in Connected Automated Vehicles
Shengye Pang,, Yi Li, Zhen Qin, Xinkui Zhao*, Jintao Chen, Fan Wang, Jianwei Yin (* corresponding author)
ACM Transactions on Autonomous and Adaptive Systems (TAAS) 2024
The Intelligent Transportation System (ITS) serves as a pivotal element within urban networks, offering decision support to users and connected automated vehicles (CAVs) through comprehensive information gathering, sensing, device control, and data processing. Presently, ITS predominantly relies on sensors embedded in fixed infrastructure, notably Roadside Units (RSUs). However, RSUs are confined by coverage limitations and may encounter challenges in prompt emergency responses. On-demand resources, such as drones, present a viable option to supplement these deficiencies effectively. This paper introduces an approach where Software-Defined Networking (SDN) and Mobile Edge Computing (MEC) technologies are integrated to formulate a high-availability drone swarm control and communication infrastructure framework, comprising the cloud layer, edge layer, and device layer. Drones confront limitations in flight duration attributed to battery limitations, posing a challenge in sustaining continuous monitoring of road conditions over extended periods. Effective drone scheduling stands as a promising solution to overcome these constraints. To tackle this issue, we initially utilized Graph WaveNet, a specialized graph neural network structure tailored for spatial-temporal graph modeling, for training a congestion prediction model using real-world dataset inputs. Building upon this, we further propose an algorithm for drone scheduling based on congestion prediction. Our simulation experiments using real-world data demonstrate that, compared to the baseline method, the proposed scheduling algorithm not only yielded superior scheduling gains but also mitigated drone idle rates.
Adaptive Scheduling of High-Availability Drone Swarms for Congestion Alleviation in Connected Automated Vehicles
Shengye Pang,, Yi Li, Zhen Qin, Xinkui Zhao*, Jintao Chen, Fan Wang, Jianwei Yin (* corresponding author)
ACM Transactions on Autonomous and Adaptive Systems (TAAS) 2024
The Intelligent Transportation System (ITS) serves as a pivotal element within urban networks, offering decision support to users and connected automated vehicles (CAVs) through comprehensive information gathering, sensing, device control, and data processing. Presently, ITS predominantly relies on sensors embedded in fixed infrastructure, notably Roadside Units (RSUs). However, RSUs are confined by coverage limitations and may encounter challenges in prompt emergency responses. On-demand resources, such as drones, present a viable option to supplement these deficiencies effectively. This paper introduces an approach where Software-Defined Networking (SDN) and Mobile Edge Computing (MEC) technologies are integrated to formulate a high-availability drone swarm control and communication infrastructure framework, comprising the cloud layer, edge layer, and device layer. Drones confront limitations in flight duration attributed to battery limitations, posing a challenge in sustaining continuous monitoring of road conditions over extended periods. Effective drone scheduling stands as a promising solution to overcome these constraints. To tackle this issue, we initially utilized Graph WaveNet, a specialized graph neural network structure tailored for spatial-temporal graph modeling, for training a congestion prediction model using real-world dataset inputs. Building upon this, we further propose an algorithm for drone scheduling based on congestion prediction. Our simulation experiments using real-world data demonstrate that, compared to the baseline method, the proposed scheduling algorithm not only yielded superior scheduling gains but also mitigated drone idle rates.
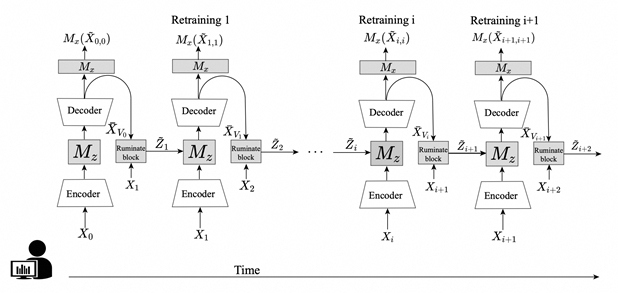
LARA: A Light and Anti-overfitting Retraining Approach for Unsupervised Time Series Anomaly Detection
Feiyi Chen, Zhen Qin, Mengchu Zhou, Yingying Zhang, Shuiguang Deng*, Lunting Fan, Guansong Pang, Qingsong Wen (* corresponding author)
The Web Conference (WWW) 2024
Most of current anomaly detection models assume that the normal pattern remains the same all the time. However, the normal patterns of web services can change dramatically and frequently over time. The model trained on old-distribution data becomes outdated and ineffective after such changes. Retraining the whole model whenever the pattern is changed is computationally expensive. Further, at the beginning of normal pattern changes, there is not enough observation data from the new distribution. Retraining a large neural network model with limited data is vulnerable to overfitting. Thus, we propose a Light Anti-overfitting Retraining Approach (LARA) based on deep variational auto-encoders for time series anomaly detection. In LARA we make the following three major contributions: 1) the retraining process is designed as a convex problem such that overfitting is prevented and the retraining process can converge fast; 2) a novel ruminate block is introduced, which can leverage the historical data without the need to store them; 3) we mathematically and experimentally prove that when fine-tuning the latent vector and reconstructed data, the linear formations can achieve the least adjusting errors between the ground truths and the fine-tuned ones. Moreover, we have performed many experiments to verify that retraining LARA with even a limited amount of data from new distribution can achieve competitive performance in comparison with the state-of-the-art anomaly detection models trained with sufficient data. Besides, we verify its light computational overhead.
LARA: A Light and Anti-overfitting Retraining Approach for Unsupervised Time Series Anomaly Detection
Feiyi Chen, Zhen Qin, Mengchu Zhou, Yingying Zhang, Shuiguang Deng*, Lunting Fan, Guansong Pang, Qingsong Wen (* corresponding author)
The Web Conference (WWW) 2024
Most of current anomaly detection models assume that the normal pattern remains the same all the time. However, the normal patterns of web services can change dramatically and frequently over time. The model trained on old-distribution data becomes outdated and ineffective after such changes. Retraining the whole model whenever the pattern is changed is computationally expensive. Further, at the beginning of normal pattern changes, there is not enough observation data from the new distribution. Retraining a large neural network model with limited data is vulnerable to overfitting. Thus, we propose a Light Anti-overfitting Retraining Approach (LARA) based on deep variational auto-encoders for time series anomaly detection. In LARA we make the following three major contributions: 1) the retraining process is designed as a convex problem such that overfitting is prevented and the retraining process can converge fast; 2) a novel ruminate block is introduced, which can leverage the historical data without the need to store them; 3) we mathematically and experimentally prove that when fine-tuning the latent vector and reconstructed data, the linear formations can achieve the least adjusting errors between the ground truths and the fine-tuned ones. Moreover, we have performed many experiments to verify that retraining LARA with even a limited amount of data from new distribution can achieve competitive performance in comparison with the state-of-the-art anomaly detection models trained with sufficient data. Besides, we verify its light computational overhead.

BlockDFL: A Blockchain-based Fully Decentralized Peer-to-Peer Federated Learning Framework
Zhen Qin, Xueqiang Yan, Mengchu Zhou, Shuiguang Deng* (* corresponding author)
The Web Conference (WWW) 2024
Federated learning (FL) enables the collaborative training of machine learning models without sharing training data. Traditional FL heavily relies on a trusted centralized server. Although decentralized FL eliminates the dependence on a centralized server, it faces such issues as poisoning attacks and data representation leakage due to insufficient restrictions on the behavior of participants, and heavy communication costs in fully decentralized scenarios, i.e., peer-to-peer (P2P) settings. This work proposes a blockchainbased fully decentralized P2P framework for FL, called BlockDFL. It takes blockchain as the foundation, leveraging the proposed voting mechanism and a two-layer scoring mechanism to coordinate FL among participants without mutual trust, while effectively defending against poisoning attacks. Gradient compression is introduced to lower communication cost and to prevent data from being reconstructed from transmitted model updates. The results of extensive experiments conducted on two real-world datasets exhibit that BlockDFL obtains competitive accuracy compared to centralized FL and can defend against poisoning attacks while achieving efficiency and scalability. Especially when the proportion of malicious participants is as high as 40%, BlockDFL can still preserve the accuracy of FL, outperforming existing fully decentralized P2P FL frameworks based on blockchain.
BlockDFL: A Blockchain-based Fully Decentralized Peer-to-Peer Federated Learning Framework
Zhen Qin, Xueqiang Yan, Mengchu Zhou, Shuiguang Deng* (* corresponding author)
The Web Conference (WWW) 2024
Federated learning (FL) enables the collaborative training of machine learning models without sharing training data. Traditional FL heavily relies on a trusted centralized server. Although decentralized FL eliminates the dependence on a centralized server, it faces such issues as poisoning attacks and data representation leakage due to insufficient restrictions on the behavior of participants, and heavy communication costs in fully decentralized scenarios, i.e., peer-to-peer (P2P) settings. This work proposes a blockchainbased fully decentralized P2P framework for FL, called BlockDFL. It takes blockchain as the foundation, leveraging the proposed voting mechanism and a two-layer scoring mechanism to coordinate FL among participants without mutual trust, while effectively defending against poisoning attacks. Gradient compression is introduced to lower communication cost and to prevent data from being reconstructed from transmitted model updates. The results of extensive experiments conducted on two real-world datasets exhibit that BlockDFL obtains competitive accuracy compared to centralized FL and can defend against poisoning attacks while achieving efficiency and scalability. Especially when the proportion of malicious participants is as high as 40%, BlockDFL can still preserve the accuracy of FL, outperforming existing fully decentralized P2P FL frameworks based on blockchain.
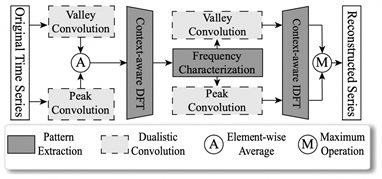
Learning Multi-Pattern Normalities in the Frequency Domain for Efficient Time Series Anomaly Detection
Feiyi Chen, Yingying Zhang, Zhen Qin, Lunting Fan, Renhe Jiang, Yuxuan Liang, Qingsong Wen, Shuiguang Deng* (* corresponding author)
International Conference on Data Engineering (ICDE) 2024
Pre-trained large language models (LLMs) require fine-tuning to improve their responsiveness to natural language instructions. Federated learning (FL) offers a way to perform fine-tuning using the abundant data on end devices without compromising data privacy. Most existing federated fine-tuning methods for LLMs rely on parameter-efficient fine-tuning techniques, which may not reach the performance heights possible with full-parameter tuning. However, the communication overhead associated with full-parameter tuning is prohibitively high for both servers and clients. This work introduces FedKSeed, a novel approach that employs zeroth-order optimization (ZOO) with a set of random seeds. It enables federated full-parameter tuning of billion-sized LLMs directly on devices. Our method significantly reduces transmission requirements between the server and clients to just a few scalar gradients and random seeds, amounting to only a few thousand bytes. Building on this, we develop a strategy to assess the significance of ZOO perturbations for FL, allowing for probability-differentiated seed sampling. This prioritizes perturbations that have a greater impact on model accuracy. Experiments across six scenarios with different LLMs, datasets and data partitions demonstrate that our approach outperforms existing federated LLM fine-tuning methods in terms of both communication efficiency and new task generalization.
Learning Multi-Pattern Normalities in the Frequency Domain for Efficient Time Series Anomaly Detection
Feiyi Chen, Yingying Zhang, Zhen Qin, Lunting Fan, Renhe Jiang, Yuxuan Liang, Qingsong Wen, Shuiguang Deng* (* corresponding author)
International Conference on Data Engineering (ICDE) 2024
Pre-trained large language models (LLMs) require fine-tuning to improve their responsiveness to natural language instructions. Federated learning (FL) offers a way to perform fine-tuning using the abundant data on end devices without compromising data privacy. Most existing federated fine-tuning methods for LLMs rely on parameter-efficient fine-tuning techniques, which may not reach the performance heights possible with full-parameter tuning. However, the communication overhead associated with full-parameter tuning is prohibitively high for both servers and clients. This work introduces FedKSeed, a novel approach that employs zeroth-order optimization (ZOO) with a set of random seeds. It enables federated full-parameter tuning of billion-sized LLMs directly on devices. Our method significantly reduces transmission requirements between the server and clients to just a few scalar gradients and random seeds, amounting to only a few thousand bytes. Building on this, we develop a strategy to assess the significance of ZOO perturbations for FL, allowing for probability-differentiated seed sampling. This prioritizes perturbations that have a greater impact on model accuracy. Experiments across six scenarios with different LLMs, datasets and data partitions demonstrate that our approach outperforms existing federated LLM fine-tuning methods in terms of both communication efficiency and new task generalization.

Resisting Backdoor Attacks in Federated Learning via Bidirectional Elections and Individual Perspective
Zhen Qin, Feiyi Chen, Chen Zhi, Xueqiang Yan, Shuiguang Deng* (* corresponding author)
AAAI Conference on Artificial Intelligence (AAAI) 2024
Existing approaches defend against backdoor attacks in federated learning (FL) mainly through a) mitigating the impact of infected models, or b) excluding infected models. The former negatively impacts model accuracy, while the latter usually relies on globally clear boundaries between benign and infected model updates. However, in reality, model updates can easily become mixed and scattered throughout due to the diverse distributions of local data. This work focuses on excluding infected models in FL. Unlike previous perspectives from a global view, we propose Snowball, a novel anti-backdoor FL framework through bidirectional elections from an individual perspective inspired by one principle deduced by us and two principles in FL and deep learning. It is characterized by a) bottom-up election, where each candidate model update votes to several peer ones such that a few model updates are elected as selectees for aggregation; and b) top-down election, where selectees progressively enlarge themselves through picking up from the candidates. We compare Snowball with state-of-the-art defenses to backdoor attacks in FL on five real-world datasets, demonstrating its superior resistance to backdoor attacks and slight impact on the accuracy of the global model.
Resisting Backdoor Attacks in Federated Learning via Bidirectional Elections and Individual Perspective
Zhen Qin, Feiyi Chen, Chen Zhi, Xueqiang Yan, Shuiguang Deng* (* corresponding author)
AAAI Conference on Artificial Intelligence (AAAI) 2024
Existing approaches defend against backdoor attacks in federated learning (FL) mainly through a) mitigating the impact of infected models, or b) excluding infected models. The former negatively impacts model accuracy, while the latter usually relies on globally clear boundaries between benign and infected model updates. However, in reality, model updates can easily become mixed and scattered throughout due to the diverse distributions of local data. This work focuses on excluding infected models in FL. Unlike previous perspectives from a global view, we propose Snowball, a novel anti-backdoor FL framework through bidirectional elections from an individual perspective inspired by one principle deduced by us and two principles in FL and deep learning. It is characterized by a) bottom-up election, where each candidate model update votes to several peer ones such that a few model updates are elected as selectees for aggregation; and b) top-down election, where selectees progressively enlarge themselves through picking up from the candidates. We compare Snowball with state-of-the-art defenses to backdoor attacks in FL on five real-world datasets, demonstrating its superior resistance to backdoor attacks and slight impact on the accuracy of the global model.
2023

FedAPEN: Personalized Cross-silo Federated Learning with Adaptability to Statistical Heterogeneity
Zhen Qin, Shuiguang Deng*, Mingyu Zhao, Xueqiang Yan (* corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2023
In cross-silo federated learning (FL), the data among clients are usually statistically heterogeneous (aka not independent and identically distributed, non-IID) due to diversified data sources, lowering the accuracy of FL. Although many personalized FL (PFL) approaches have been proposed to address this issue, they are only suitable for data with specific degrees of statistical heterogeneity. In the real world, the heterogeneity of data among clients is often immeasurable due to privacy concern, making the targeted selection of PFL approaches difficult. Besides, in cross-silo FL, clients are usually from different organizations, tending to hold architecturally different private models. In this work, we propose a novel FL framework, FedAPEN, which combines mutual learning and ensemble learning to take the advantages of private and shared global models while allowing heterogeneous models. Within FedAPEN, we propose two mechanisms to coordinate and promote model ensemble such that FedAPEN achieves excellent accuracy on various data distributions without prior knowledge of data heterogeneity, and thus, obtains the adaptability to data heterogeneity. We conduct extensive experiments on four real-world datasets, including: 1) Fashion MNIST, CIFAR-10, and CIFAR-100, each with ten different types and degrees of label distribution skew; and 2) eICU with feature distribution skew. The experiments demonstrate that FedAPEN almost obtains superior accuracy on data with varying types and degrees of heterogeneity compared with baselines.
FedAPEN: Personalized Cross-silo Federated Learning with Adaptability to Statistical Heterogeneity
Zhen Qin, Shuiguang Deng*, Mingyu Zhao, Xueqiang Yan (* corresponding author)
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2023
In cross-silo federated learning (FL), the data among clients are usually statistically heterogeneous (aka not independent and identically distributed, non-IID) due to diversified data sources, lowering the accuracy of FL. Although many personalized FL (PFL) approaches have been proposed to address this issue, they are only suitable for data with specific degrees of statistical heterogeneity. In the real world, the heterogeneity of data among clients is often immeasurable due to privacy concern, making the targeted selection of PFL approaches difficult. Besides, in cross-silo FL, clients are usually from different organizations, tending to hold architecturally different private models. In this work, we propose a novel FL framework, FedAPEN, which combines mutual learning and ensemble learning to take the advantages of private and shared global models while allowing heterogeneous models. Within FedAPEN, we propose two mechanisms to coordinate and promote model ensemble such that FedAPEN achieves excellent accuracy on various data distributions without prior knowledge of data heterogeneity, and thus, obtains the adaptability to data heterogeneity. We conduct extensive experiments on four real-world datasets, including: 1) Fashion MNIST, CIFAR-10, and CIFAR-100, each with ten different types and degrees of label distribution skew; and 2) eICU with feature distribution skew. The experiments demonstrate that FedAPEN almost obtains superior accuracy on data with varying types and degrees of heterogeneity compared with baselines.
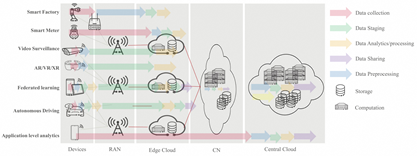
6G Data Plane: A Novel Architecture Enabling Data Collaboration with Arbitrary Topology
Zhen Qin, Shuiguang Deng*, Xueqiang Yan, Lu Lu, Mingyu Zhao, Yan Xi, Jianjun Wu, Tao Sun, Nanxiang Shi (* corresponding author)
Mobile Networks and Applications (MONET) 2023
Although the fifth-generation wireless communication network (5G) has made much progress in improving the quality of user experience by providing large bandwidth transmission, it only provides the connectivity services between user equipments (UEs) and the network. With the sensing and intelligence are envisioned to become the native capability of the sixth-generation communication network (6G), there is an urgent need for a new network architecture enabling the “on-path-data-processing”, to make better leverage of distributed and ubiquitous computation resources and data. Thus, we propose a Data Plane in 6G network, which is independent of existing User Plane, aiming at constructing data pipelines based on various data service requirements. It systematically provides the collaboration of data among multiple network components with arbitrary topology with the support for on-path-data-processing. Based on this, we propose three data forwarding control protocols, guaranteeing the operation of Data Plane by providing data forwarding in any topology. Simulation experiments demonstrate the good scalability and efficiency of the three protocols in Data Plane.
6G Data Plane: A Novel Architecture Enabling Data Collaboration with Arbitrary Topology
Zhen Qin, Shuiguang Deng*, Xueqiang Yan, Lu Lu, Mingyu Zhao, Yan Xi, Jianjun Wu, Tao Sun, Nanxiang Shi (* corresponding author)
Mobile Networks and Applications (MONET) 2023
Although the fifth-generation wireless communication network (5G) has made much progress in improving the quality of user experience by providing large bandwidth transmission, it only provides the connectivity services between user equipments (UEs) and the network. With the sensing and intelligence are envisioned to become the native capability of the sixth-generation communication network (6G), there is an urgent need for a new network architecture enabling the “on-path-data-processing”, to make better leverage of distributed and ubiquitous computation resources and data. Thus, we propose a Data Plane in 6G network, which is independent of existing User Plane, aiming at constructing data pipelines based on various data service requirements. It systematically provides the collaboration of data among multiple network components with arbitrary topology with the support for on-path-data-processing. Based on this, we propose three data forwarding control protocols, guaranteeing the operation of Data Plane by providing data forwarding in any topology. Simulation experiments demonstrate the good scalability and efficiency of the three protocols in Data Plane.
ST-EUA: Spatio-Temporal Edge User Allocation With Task Decomposition
Guobing Zou, Ya Liu, Zhen Qin, Jin Chen, Yanglan Gan*, Bofeng Chang, Qiang He* (* corresponding author)
IEEE Transactions on Services Computing (TSC) 2023
Recently, edge user allocation (EUA) problem has received much attentions. It aims to appropriately allocate edge users to their nearby edge servers. Existing EUA approaches suffer from a series of limitations. First, considering users’ service requests only as a whole, they neglect the fact that in many cases a service request may be partitioned into multiple tasks to be performed by different edge servers. Second, the impact of the spatial distance between edge users and servers on users’ quality of experience is not properly considered. Third, the temporal dynamics of users’ service requests has not been fully considered. To overcome these limitations systematically, this article focuses on the problem of spatio-temporal edge user allocation with task decomposition (ST-EUA). We first formulate the ST-EUA problem. Then, we transform ST-EUA problem as an optimization problem with multiple objectives and global constraints and prove its NP-hardness. To tackle the ST-EUA problem effectively and efficiently, we propose a novel genetic algorithm-based heuristic approach called GA-ST, aiming to maximize users’ overall QoE while minimizing the cost of task migration in different time slots. Extensive experiments are conducted on two widely-used real-world datasets to evaluate the performance of our approach. The results demonstrate that GA-ST significantly outperforms state-of-the-art approaches in finding approximate solutions in terms of the trade-off among multiple metrics.
ST-EUA: Spatio-Temporal Edge User Allocation With Task Decomposition
Guobing Zou, Ya Liu, Zhen Qin, Jin Chen, Yanglan Gan*, Bofeng Chang, Qiang He* (* corresponding author)
IEEE Transactions on Services Computing (TSC) 2023
Recently, edge user allocation (EUA) problem has received much attentions. It aims to appropriately allocate edge users to their nearby edge servers. Existing EUA approaches suffer from a series of limitations. First, considering users’ service requests only as a whole, they neglect the fact that in many cases a service request may be partitioned into multiple tasks to be performed by different edge servers. Second, the impact of the spatial distance between edge users and servers on users’ quality of experience is not properly considered. Third, the temporal dynamics of users’ service requests has not been fully considered. To overcome these limitations systematically, this article focuses on the problem of spatio-temporal edge user allocation with task decomposition (ST-EUA). We first formulate the ST-EUA problem. Then, we transform ST-EUA problem as an optimization problem with multiple objectives and global constraints and prove its NP-hardness. To tackle the ST-EUA problem effectively and efficiently, we propose a novel genetic algorithm-based heuristic approach called GA-ST, aiming to maximize users’ overall QoE while minimizing the cost of task migration in different time slots. Extensive experiments are conducted on two widely-used real-world datasets to evaluate the performance of our approach. The results demonstrate that GA-ST significantly outperforms state-of-the-art approaches in finding approximate solutions in terms of the trade-off among multiple metrics.
2022

DeepWSC: Clustering Web Services via Integrating Service Composability into Deep Semantic Features
Guobing Zou, Zhen Qin, Qiang He, Pengwei Wang, Bofeng Zhang, Yanglan Gan* (* corresponding author)
IEEE Transactions on Services Computing (TSC) 2022
With an growing number of web services available on the Internet, an increasing burden is imposed on the use and management of service repository. Service clustering has been employed to facilitate a wide range of service-oriented tasks, such as service discovery, selection, composition and recommendation. Conventional approaches have been proposed to cluster web services by using explicit features, including syntactic features contained in service descriptions or semantic features extracted by probabilistic topic models. However, service implicit features are ignored and have yet to be properly explored and leveraged. To this end, we propose a novel heuristics-based framework DeepWSC for web service clustering. It integrates deep semantic features extracted from service descriptions by an improved recurrent convolutional neural network and service composability features obtained from service invocation relationships by a signed graph convolutional network, to jointly generate integrated implicit features for web service clustering. Extensive experiments are conducted on 8,459 real-world web services. The experiment results demonstrate that DeepWSC outperforms state-of-the-art approaches for web service clustering in terms of multiple evaluation metrics.
DeepWSC: Clustering Web Services via Integrating Service Composability into Deep Semantic Features
Guobing Zou, Zhen Qin, Qiang He, Pengwei Wang, Bofeng Zhang, Yanglan Gan* (* corresponding author)
IEEE Transactions on Services Computing (TSC) 2022
With an growing number of web services available on the Internet, an increasing burden is imposed on the use and management of service repository. Service clustering has been employed to facilitate a wide range of service-oriented tasks, such as service discovery, selection, composition and recommendation. Conventional approaches have been proposed to cluster web services by using explicit features, including syntactic features contained in service descriptions or semantic features extracted by probabilistic topic models. However, service implicit features are ignored and have yet to be properly explored and leveraged. To this end, we propose a novel heuristics-based framework DeepWSC for web service clustering. It integrates deep semantic features extracted from service descriptions by an improved recurrent convolutional neural network and service composability features obtained from service invocation relationships by a signed graph convolutional network, to jointly generate integrated implicit features for web service clustering. Extensive experiments are conducted on 8,459 real-world web services. The experiment results demonstrate that DeepWSC outperforms state-of-the-art approaches for web service clustering in terms of multiple evaluation metrics.
2021

Towards the optimality of service instance selection in mobile edge computing
Guobing Zou, Zhen Qin, Shuiguang Deng, Kuan-Ching Li, Yanglan Gan*, Bofeng Zhang* (* corresponding author)
IEEE Transactions on Pattern Analysis and Machine Intelligence 2021
Mobile edge computing (MEC) has been proposed to significantly reduce the response time of service invocations for end users. In MEC environment, a service provider can create multiple instances from a service and deploy them to different hired edge servers, where the deployed instances can be selected and invoked to decrease the network latency by nearby users. However, service instance selection in MEC is a challenging research problem from threefold aspects. First, the limitations of an edge server in terms of computation capacity and coverage range result in serving for only a certain number of users at the same time. Second, due to variable geographical locations from user mobility paths in MEC, the mobility of edge users is highly related to data transmission rate and affects the delay of service invocations. Furthermore, when many users in an edge server covered region request the same service instance at the same time, they interfere with each other and may reduce the experience of service invocations if there is no effective strategy to distribute these requests to appropriate instances deployed on different edge servers. To improve the user experience on service invocations with a lower response time, we take the above three factors into account and model the service instance selection problem (SISP) in MEC as an optimization problem, and propose a novel genetic algorithm-based approach with a response time-aware mutation operation with normalization for service instance selection called GASISMEC to find approximately optimal solution. Extensive experiments are conducted on two widely-used real-world datasets. The results demonstrate that our approach significantly outperforms the six baseline competing approaches.
Towards the optimality of service instance selection in mobile edge computing
Guobing Zou, Zhen Qin, Shuiguang Deng, Kuan-Ching Li, Yanglan Gan*, Bofeng Zhang* (* corresponding author)
IEEE Transactions on Pattern Analysis and Machine Intelligence 2021
Mobile edge computing (MEC) has been proposed to significantly reduce the response time of service invocations for end users. In MEC environment, a service provider can create multiple instances from a service and deploy them to different hired edge servers, where the deployed instances can be selected and invoked to decrease the network latency by nearby users. However, service instance selection in MEC is a challenging research problem from threefold aspects. First, the limitations of an edge server in terms of computation capacity and coverage range result in serving for only a certain number of users at the same time. Second, due to variable geographical locations from user mobility paths in MEC, the mobility of edge users is highly related to data transmission rate and affects the delay of service invocations. Furthermore, when many users in an edge server covered region request the same service instance at the same time, they interfere with each other and may reduce the experience of service invocations if there is no effective strategy to distribute these requests to appropriate instances deployed on different edge servers. To improve the user experience on service invocations with a lower response time, we take the above three factors into account and model the service instance selection problem (SISP) in MEC as an optimization problem, and propose a novel genetic algorithm-based approach with a response time-aware mutation operation with normalization for service instance selection called GASISMEC to find approximately optimal solution. Extensive experiments are conducted on two widely-used real-world datasets. The results demonstrate that our approach significantly outperforms the six baseline competing approaches.
2020
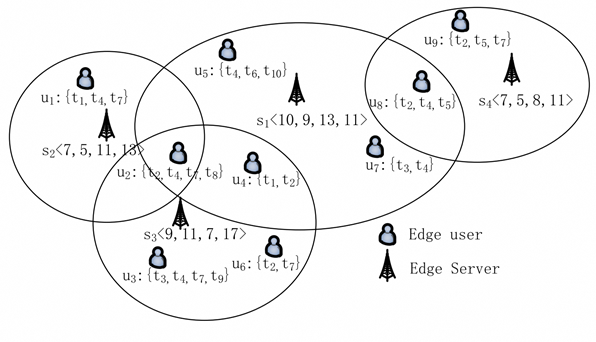
TD-EUA: Task-Decomposable Edge User Allocation with QoE Optimization
Guobing Zou, Ya Liu, Zhen Qin*, Jin Chen, Zhiwei Xu, Yanglan Gan, Bofeng Zhang, Qiang He* (* corresponding author)
International Conference on Service-Oriented Computing (ICSOC) 2020
The edge user allocation (EUA) problem has attracted a lot of attention recently. EUA aims at allocating edge users to nearby edge servers strategically to ensure low-latency network connection. Existing approaches assume that a users’ request can only be served by an individual edge server or cannot be served at all. They neglect the fact that a user’s request may be decomposable and partitioned into multiple tasks to be performed by different edge servers. To tackle this new task-decomposable edge user allocation (TD-EUA) problem, we model it as an optimization problem. Two novel approaches named TD-EUA-O and TD-EUA-H are proposed, one for finding the optimal solution based on Integer Linear Programming that maximizes users’ overall Quality of Experience (QoE), and the other for efficiently finding a sub-optimal solution in large-scale EUA scenarios. Extensive experiments based on a widely-used real-world dataset are conducted to evaluate the effectiveness and efficiency of our approaches. The results demonstrate that our approaches significantly outperform the baseline and the state-of-the-art approach.
TD-EUA: Task-Decomposable Edge User Allocation with QoE Optimization
Guobing Zou, Ya Liu, Zhen Qin*, Jin Chen, Zhiwei Xu, Yanglan Gan, Bofeng Zhang, Qiang He* (* corresponding author)
International Conference on Service-Oriented Computing (ICSOC) 2020
The edge user allocation (EUA) problem has attracted a lot of attention recently. EUA aims at allocating edge users to nearby edge servers strategically to ensure low-latency network connection. Existing approaches assume that a users’ request can only be served by an individual edge server or cannot be served at all. They neglect the fact that a user’s request may be decomposable and partitioned into multiple tasks to be performed by different edge servers. To tackle this new task-decomposable edge user allocation (TD-EUA) problem, we model it as an optimization problem. Two novel approaches named TD-EUA-O and TD-EUA-H are proposed, one for finding the optimal solution based on Integer Linear Programming that maximizes users’ overall Quality of Experience (QoE), and the other for efficiently finding a sub-optimal solution in large-scale EUA scenarios. Extensive experiments based on a widely-used real-world dataset are conducted to evaluate the effectiveness and efficiency of our approaches. The results demonstrate that our approaches significantly outperform the baseline and the state-of-the-art approach.
2019

DeepWSC: A Novel Framework with Deep Neural Network for Web Service Clustering
Guobing Zou, Zhen Qin, Qiang He, Pengwei Wang, Bofeng Zhang, Yanglan Gan* (* corresponding author)
IEEE International Conference on Web Services (ICWS) 2019
Correlative approaches have attempted to cluster web services based on either the explicit information contained in service descriptions or functionality semantic features extracted by probabilistic topic models. However, the implicit contextual information of service descriptions is ignored and has yet to be properly explored and leveraged. To this end, we propose a novel framework with deep neural network, called DeepWSC, which combines the advantages of recurrent neural network and convolutional neural network to cluster web services through automatic feature extraction. The experimental results demonstrate that DeepWSC outperforms state-of-the-art approaches for web service clustering in terms of multiple evaluation metrics.
DeepWSC: A Novel Framework with Deep Neural Network for Web Service Clustering
Guobing Zou, Zhen Qin, Qiang He, Pengwei Wang, Bofeng Zhang, Yanglan Gan* (* corresponding author)
IEEE International Conference on Web Services (ICWS) 2019
Correlative approaches have attempted to cluster web services based on either the explicit information contained in service descriptions or functionality semantic features extracted by probabilistic topic models. However, the implicit contextual information of service descriptions is ignored and has yet to be properly explored and leveraged. To this end, we propose a novel framework with deep neural network, called DeepWSC, which combines the advantages of recurrent neural network and convolutional neural network to cluster web services through automatic feature extraction. The experimental results demonstrate that DeepWSC outperforms state-of-the-art approaches for web service clustering in terms of multiple evaluation metrics.